
Mobile Architecture at UpKeep Part 1: KMP & Clean Architecture
Mobile app architecture (iOS/Android) at UpKeep - Kotlin Multiplatform for code reusability + RIBs (Router Interactor Builder) for scalability. Part 1 of a 2-part series on iOS architecture at UpKeep.


At UpKeep we have a small mobile team that supports a rich feature set of our CMMS application. We have native mobile apps for iOS and Android and the main users are technicians in the field performing maintenance work on assets in various facilities such as factories, warehouses, etc.
Both apps are native apps that utilize native platform capabilities. As the feature set of both apps grew over the years, it became increasingly difficult to avoid subtle (or not so subtle) discrepancies between the two native app implementations. Sometimes some bugs will creep in on one platform or the other or one platform would use slightly different data fetching or permission logic. All of these add up to a degraded user experience and an added cost of “synchronization” between two platforms, either at the development stage (where devs from both platforms need to be in sync) or at the later bug fixing stage (where Android and iOS devs would need to dig through the discrepancies and figure out which platform actually behaves correctly and which one does not). Ultimately, we always had to write the implementation twice in Kotlin and Swift (since the two apps have the same features and are supposed to behave the same way).
All of that led us to exploring cross platform and multiplatform solutions and we zeroed in on Kotlin Multiplatform (KMP) as our technology choice.
In this article we’ll cover:
Advantages of adopting KMP as a code-sharing technology over other options
A high-level overview of the architecture of UpKeep’s mobile apps and the KMP integration
Our team’s learnings and path forward
This is part 1 of a two-part series covering UpKeep’s mobile app architecture. This article will focus on the Kotlin Multiplatform side. In part 2 we’ll cover iOS application architecture in more detail.
Why KMP?
What is KMP?
KMP is a technology that allows Kotlin code to be shared and run as native code on various platforms such as iOS, Android, web, desktop, etc. KMP allows developers to write common business logic once and share it across different platforms while keeping the platform-specific code in separate modules.
What are the benefits?
Here’s an excerpt from our internal documentation that we circulated in the mobile team to get buy-in prior to embarking on adopting KMP in our codebases.
KMP provides several benefits:
Code Reusability (Unified Codebase): With KMP, you can write your business logic in a single codebase and share it across different platforms like Android, iOS, web, and desktop. This eliminates the need to duplicate efforts for each platform.
Maintenance: Maintaining one set of business logic is easier and less error-prone than maintaining multiple versions for different platforms. Bug fixes and updates can be made in one place and immediately benefit all platforms.
Consistent Behavior: Shared business logic ensures that the core functionality of your app behaves the same way on all platforms. This consistency improves the user experience as users get the same features and behavior regardless of the device they use.
Consistent Testing: Automated tests can be written once for the shared code, ensuring that all platforms meet the same quality standards. This reduces the risk of platform-specific bugs and discrepancies.
Reduced Development Time: Developing features and fixes once and deploying them across multiple platforms speeds up the development process. This allows developers to focus more on platform-specific enhancements and user experience rather than replicating business logic.
Resource Utilization: Teams can be more flexible and efficient. Instead of having separate teams for each platform working on the same feature, a single team can develop the shared logic while smaller platform-specific teams integrate and enhance it.
Maintaining Platform Independence & Flexibility: While KMP promotes sharing code, it also allows for platform-specific code where necessary. This flexibility ensures that you can optimize and customize the user experience for each platform.
Separation of Concerns: Platform-specific code can handle unique platform capabilities, UI components, and performance optimizations, while the shared code focuses on the business logic.
General Architectural Forcing Function: In general, using KMP forces developers to think through the business logic as a separate concept, clearly separated from the rest of the code, which in turn makes architecture much more robust and flexible.
What was the approach to roll it out?
Since most of the team was pretty new to KMP, we decided to take it slow and first build out a demo application as a proof-of-concept (POC) of how KMP works and its benefits. Later on, after the team was happy with the results and talked through the POC codebase extensively, we integrated KMP into our main Android and iOS codebases.
Since KMP is flexible and can be used adhoc we first refactored an existing feature with KMP and rolled it out behind a feature flag. This way, there was no surprises on the expected behavior, we could clearly validate before and after impact (there would be no change which is good in this case), and we had total control over it at runtime and could shut down the KMP refactored code path at any point in time if it was not working properly.
After a successful first attempt, we now use KMP for every new feature we develop in our mobile applications.
Mobile Architecture At UpKeep
How much code to share?
The introduction of KMP forced us to clearly articulate and define architectural boundaries in our mobile apps. The first discussion and decision that we made was how much code we should share between platforms.
These days, KMP offers a full end-to-end stack for code sharing that includes all the networking/service layer, storage layer, business logic, and UI code sharing. With KMP, you can choose to share as much or as little code as you want.
We decided to leverage the native UI on each platform to provide the best possible user experience. Therefore, we settled on sharing only the business logic code between iOS and Android for now. There is an asterisk to it though, which I’ll get into more later on.
What is Business Logic?
In a typical client side application there are two types of business logic:
The business logic of orchestrating network requests and database queries based on user input and general serialization, data mapping and processing, etc.
Management of business scopes (and screens), navigational behavior, and overall application state (screen hierarchy) as the user navigates across the app
It doesn’t matter what kind of architecture (or lack thereof) your app has, the business logic of your app will always encompass those two overall areas, regardless of whether it’s expressed explicitly or implicitly in the code.
The first group of business logic can be depicted like this:
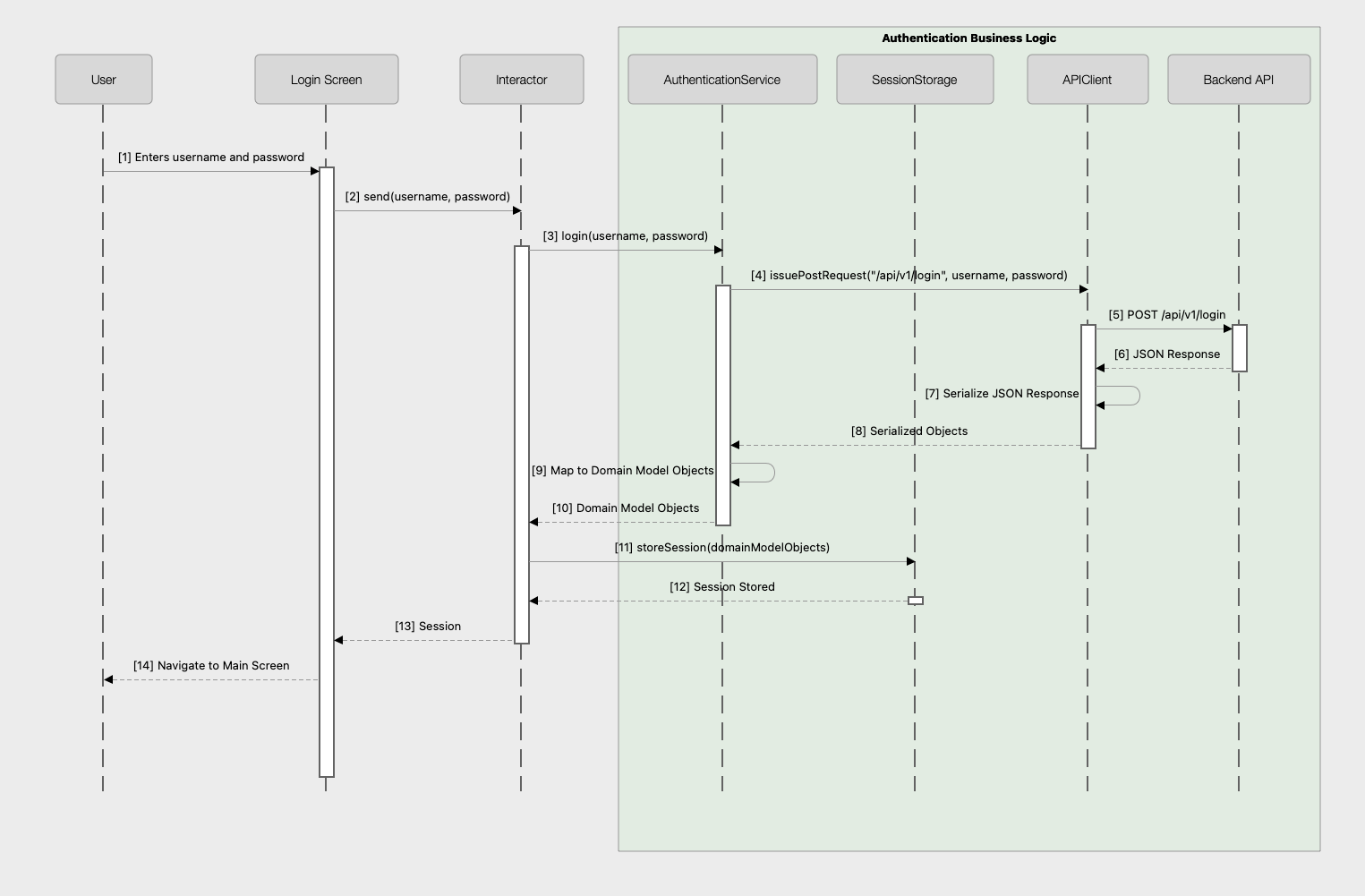
(Authentication Business Logic Flow is in green)
Here, we are covering all the logic needed to make the “machinery” of the app work. After receiving user input to, for example, the login, the app needs to process and validate the input, form a proper network request to fulfill the backend API contract and issue the request. After that, the app needs to process the response, validate that it meets the contract expectations, serialize it, map it to domain models, and then, perhaps in case of a login, persist some of the response, such as session token, to disk.
All of these things are the “plumbing” but also the business logic every app has. These are not UI-related concerns.
The second group of business logic can be depicted like this:
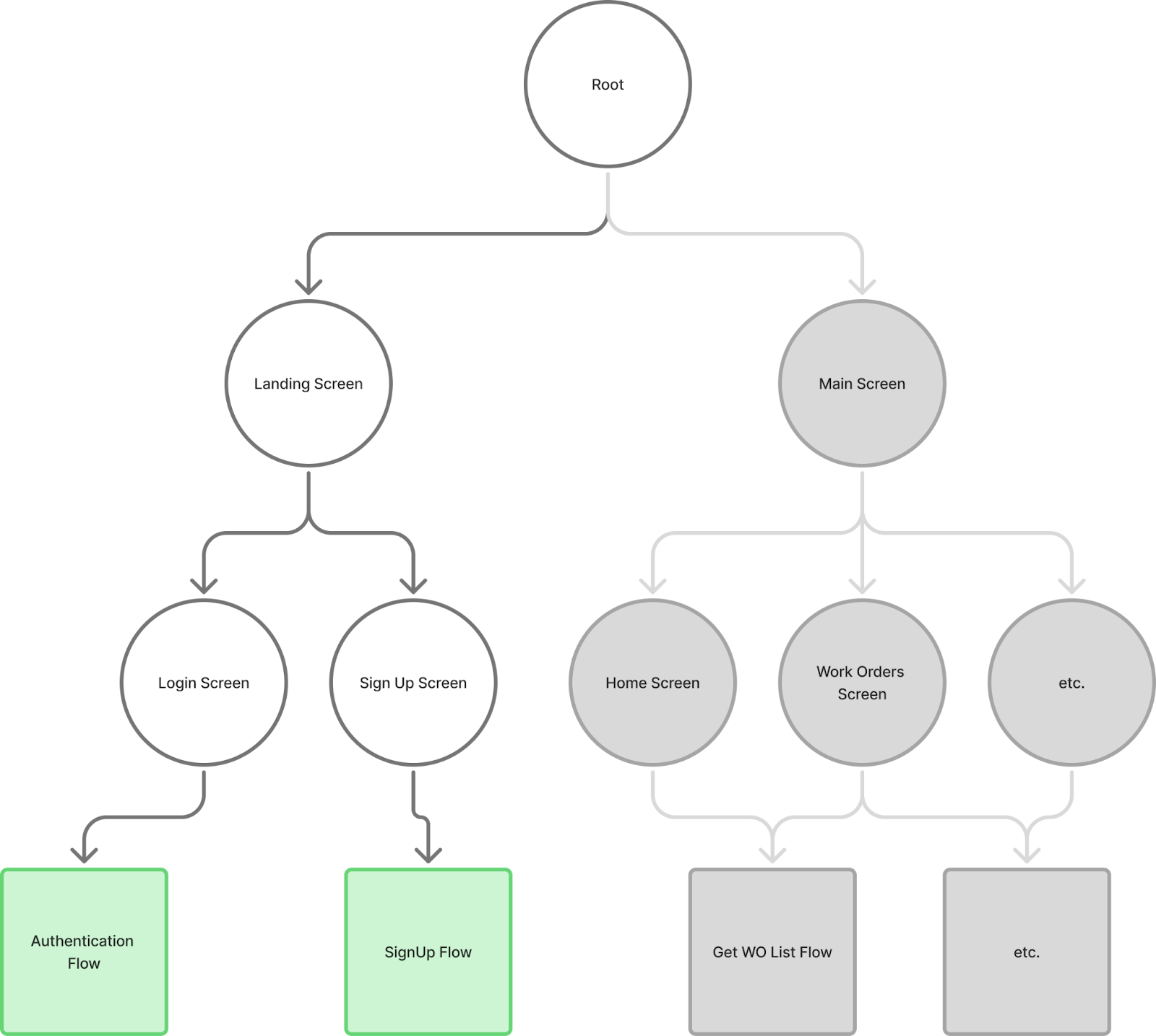
(note grey is currently inactive application scopes/state)
This is where we manage the overall application state, what screens go first and second as the user interacts with the app, where the user should be navigated to after login or tapping on a feature tab/item, etc.
It also controls when the complex business flows (such as the authentication business logic flow above) should be triggered based on user input or other events.
Note, when I say “application state,” I mean the state that needs to support the above logic, not all the UI state of what strings and images to display in a given screen (we’re talking overall application flow here).
This typically ends up being represented as a tree of business scopes or a tree of screens the application has. Everything starts with a root and then business logic decisions are made such as to route to a login screen if the user token is not present. Later, the business logic here decides to route to the main screen upon user login or other types of navigation. Or, after the user inputs some data in the UI, a use case is executed to actually perform a request on the user's behalf. All that decision making on where to route/navigate the user based on the overall application state and when to trigger more complicated login (such as use cases for submitting and retrieving data) is what’s encompassed in this second group of business logic.
What part of business logic to share?
Now, as we established what those business logic groups are, we had a hard decision to make - where to draw the line on sharing the code and the business logic. We ended up picking the first group to share for the following reasons:
It’s a more clear-cut slice of mostly “functional” behavior with virtually no side effects (except occasional database persistence) that we can extract into use cases that are shared between two platforms. There would be no deviation or platform specific code or logic here except, perhaps, for the low-level specific details of data persistence and networking. But both of those concerns are fairly well established, abstracted out, and solved with current popular open source KMP libraries.
It would be ideal to share the second business logic group as well, but given that we have legacy code in our codebase with established and divergent from each other implementations between iOS and Android (iOS has some MVVMs but also a lot of RIBs, and Android is mainly on MVVM design pattern). We decided to not push it yet and not share the second group of business logic between our mobile apps yet. It will require more abstractions and more unification in the architecture of both apps to support this kind of code sharing. We are aiming for it at some point, though.
KMP Module Architecture: Clean Architecture
So, what does the architecture look like for the shared code inside of KMP?
After establishing what slice of the business logic to share, we quickly narrowed down on using Clean Architecture for it - our shared codebase would be a collection of high level business Use Cases that can be used in and shared between our mobile apps.
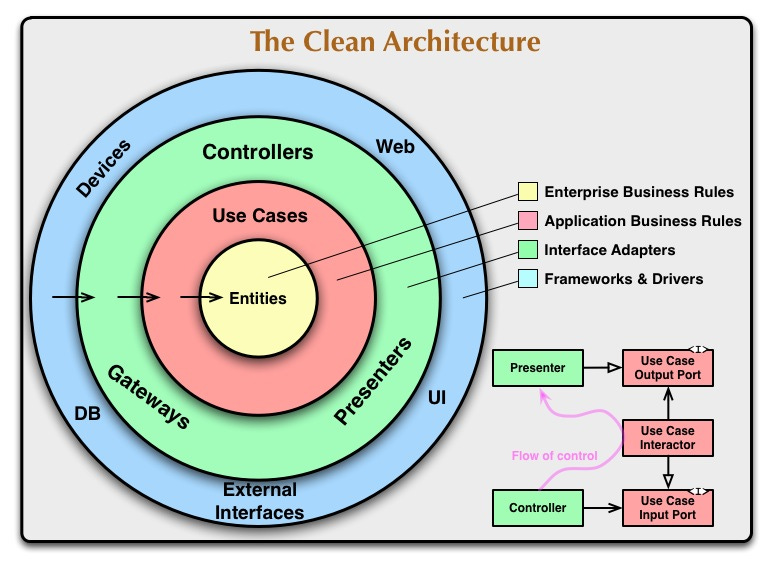
Here’s an example list of use cases we have:
UpdateNotesUseCaseUploadPhotoUseCaseGetChecklistsAndTasksUseCaseDeleteAllPhotosUseCaseDeleteSignatureUseCaseUpdateTaskValueUseCaseGetWorkOrderActiveTimerUseCaseGetWorkOrderTemplateDetailsUseCaseGetWorkOrderTemplateListUseCase
LoginUseCase Example
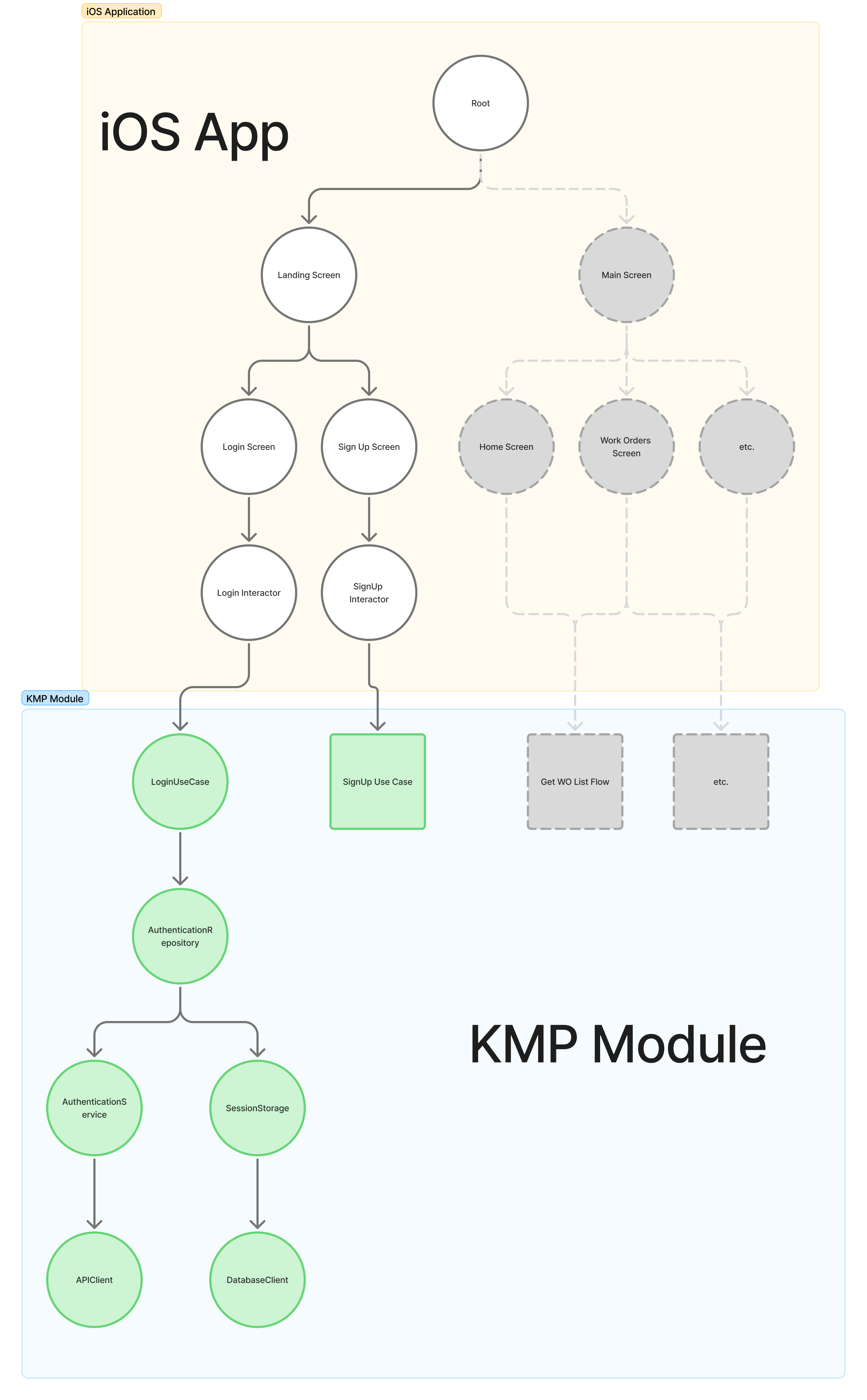
This is how our Authentication flow would work and look like for Login Screen:
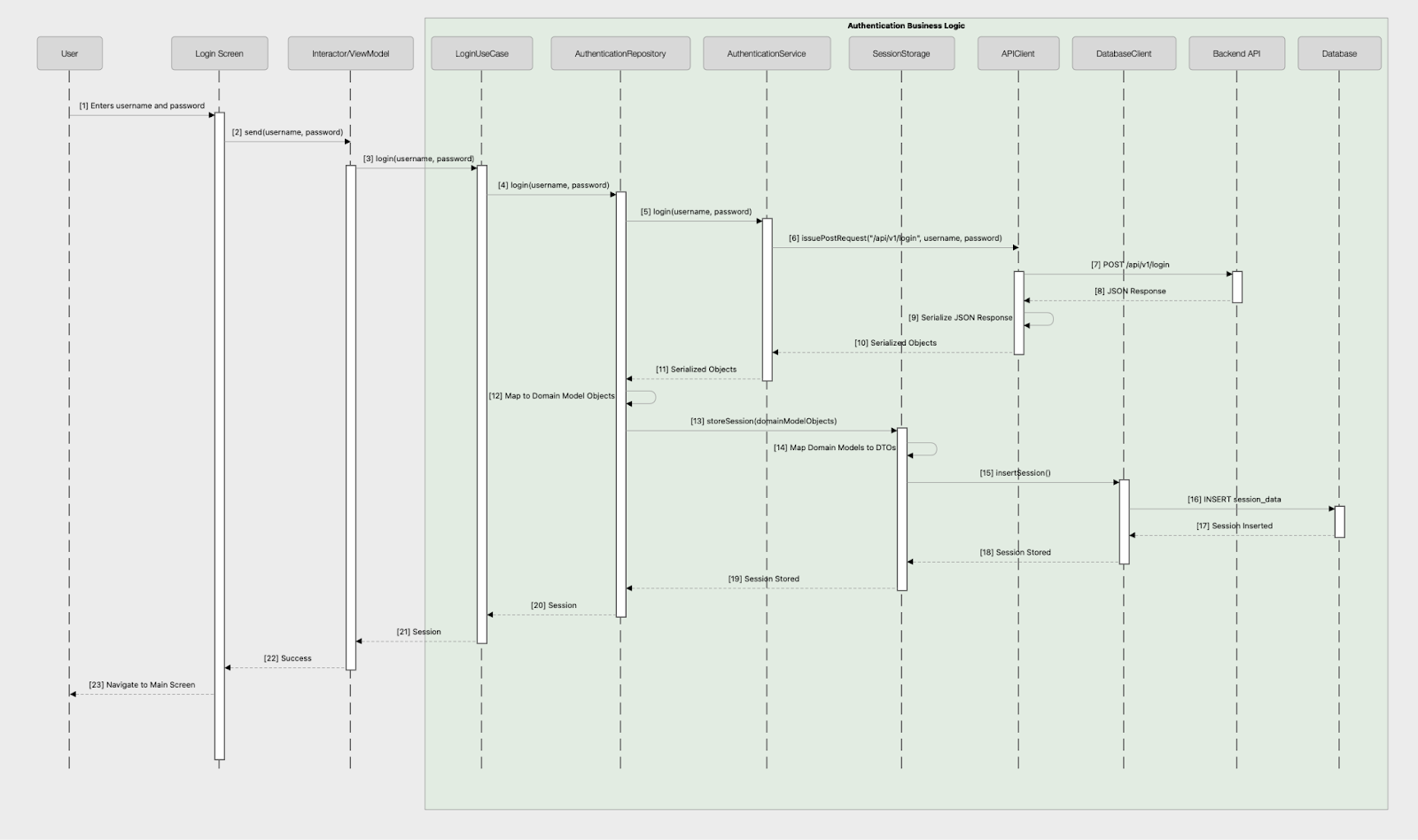
Here we have an Interactor or a ViewModel start execution of a LoginUseCase to login the user. The LoginUseCase contains all the orchestration business logic.
The LoginUseCase in turn asks AuthenticationRepository to perform whatever necessary low level logic to actually authenticate and log in the user.
The AuthenticationRepository first has AuthenticationService make a network request to authenticate the user with the backend API and to receive a session token from it.
Next the AuthenticationService uses a low level APIClient object to perform an actual HTTP request against the backend API to get the token.
After executing the HTTP request the API client serializes the response from JSON to Kotlin data class objects and returns it back to the AuthenticationService.
AuthenticationService passes the result back to AuthenticationRepository.
Then AuthenticationRepository maps the backend response to domain model objects that the rest of the app can work with. After that the repository asks SessionStorage to store the session token.
SessionStorage maps the domain models to DTO and uses DatabaseClient to store those DTOs in the actual database on device.
DatabaseClient is the one that performs low level queries to actually insert data in table/s.
After database insertion is successful, SessionStorage responds back to the AuthenticationRepository with success and AuthenticationRepository passes the authenticated token to the use case.
The LoginUseCase finally responds back to the Interactor/ViewModel about successful login so that the UI can navigate to the main user screen.
This roughly translates to the following responsibilities for each type of object:
Use Cases are responsible for business logic orchestration - i.e. what repositories to use to retrieve or send data and business logic decision making on when to call them, user permissions, validation, etc.
Repositories are responsible for data retrieval and sending. They abstract out how the data is received or stored - i.e. most of the time data is only sent or received via the backend API but sometimes it needs to be retrieved or stored in the local database, this what’s abstracted out by repositories, the use cases never need to know from where they got the data provided by repository.
Services are responsible for concrete network requests to concrete endpoints. They serialize data for sending to backend API and after receiving.
APIClients are responsible for actual mechanics of executing HTTP (or GraphQL or Socket) requests. It’s the low level object that uses URLSession or similar for actual network request sending.
Storages are responsible for storing data to disk, a database, file storage, keyvalue, doesn’t matter. Just like services for API requests, storages serialize and map data sent and received to and from the database (or other means of storage).
DatabaseClients are just like the APIClients - they are basically a wrapper around Core Data or SQL or UserDefaults or FileManager or similar that perform the actual low level data storing or retrieval function.
This is a somewhat simpler example where the use case doesn’t need to coordinate between different repositories to retrieve data but nevertheless it depicts the overall architecture of our use cases and their dependencies well.
I also omitted a bunch of helper objects that we have, in particular, the mapper objects from one layer onto another. It was a debatable subject on whether we need to have them as separate objects or if we are better off including mapping into each object such as repository, service, etc.
Modularization & Code Organization
I’ll cover modularization in detail in the next article of this series but briefly here - we modularize the shared KMP codebase by feature (i.e. Work Orders feature, Authentication feature, etc.) and by layers (database layer, networking layer, etc.)
We decided to keep shared KMP code in a standalone git repository from the iOS and Android codebases. The iOS and Android codebase import shared code as a native library.
From the developer experience point of view the shared KMP code is fetched and included in your main iOS or Android codebase as a git submodule folder so that you can change the code as you work on features full stack - both iOS/Android and KMP side at the same time.
KMP Shared Code Public API & Dependency Injection
We technically expose all of the KMP classes, including the low level ones, to the iOS and Android apps because we decided to leave dependency injection and assembly solutions to each respective application.
But the intended usage of the shared code is for iOS and Android Interactors or ViewModels to call only Use Cases from KMP and never the other objects (besides using the domain model input/output).
Architecture in iOS & Android Apps
I will cover the architecture of the iOS app (and perhaps the Android app as well) in the second part of this series. But I’ll briefly explain here how we use shared KMP use cases from the application code.
As you saw from previous diagrams the second group of business logic objects calls into Use Cases provided by the KMP code to perform useful work for the user. From the perspective of the iOS and Android apps everything is abstracted out for them. The only thing they need to do is to call the right use case at the right time and present things to the UI or route to another accordingly for the user.
Now, that is still a lot of business and UI logic that is inside of the iOS and Android apps and is not shared between them.
As mentioned before, the architectures of the iOS and the Android apps differ from each other. The iOS architecture is RIBs (Router Interactor Builder) and the Android architecture is MVVM.
On iOS Interactors are the orchestrators of business logic, they decide what needs to be presented on the screen, what use case needs to be executed and when, what next screen to route to, etc.
On Android ViewModels play a similar role but it’s not as well defined - VMs call use cases but other types of orchestration, presentation decisions, and routing happens in the view later.
We’re considering eventually moving the Android app to RIBs as well but this is in the distant future as we’re focusing on getting more things migrated to KMP across both codebases.
Learnings So Far & Path Forward
This is the third quarter for us using KMP. So far the feedback and experience have been positive. We’re able to share anywhere between 10% and 25% of the code for new features between two platforms, which is definitely a win for engineering and business. Along with it, we have better consistency and no discrepancies in how we send, retrieve, and massage data between Android and iOS where we use KMP.
Collaboration between iOS and Android engineers is at an all-time high because they now are literally working on the same codebase (at least part of it) together.
Another upside of this is that we have a brand new clean codebase with no baggage in it where we could start building things from scratch taking with us all the previous learnings on how to do and not to do things from both the iOS and the Android codebase. We have a clean and clearly defined architecture with single responsibility defined and outlined for each layer and object type.
The downside, of course, just like with any heavy architecture such as Clean Architecture, is the boilerplate - the sheer amount of files and classes needed to implement a feature is high. But because of clearly defined boundaries and responsibilities, it has not been an issue. Also, these days a lot of boilerplate code generation can be automated with LLM codegen. Since the code is so clearly defined and doesn’t have variability in each implementation, LLMs are highly useful and don’t get confused too often.
Moving forward, we’ll be adopting more and more KMP code throughout the codebases. As the rest of the architecture converges more and more between two platforms (with Android moving to RIBs) we might start considering moving the second group of business logic to the KMP side to share as well.
The last thing we will ever consider, and likely will never do, is to share UI with KMP between two platforms. UI sharing solutions such as React Native or others never work well and have too many limitations (and the same goes for KMP’s Compose Multiplatform), so it’s unlikely for us to go this direction. But even if we don’t share the UI but share 80% of the rest of the code, it will be a tremendous achievement!
On iOS are you using one umbrella framework or separate separate .framework/pod for each usecase. I have heard that in case you create multiple .frameworks from kotlin code and use it in iOS then iOS app may crash. What is your experience?
Hi Alex,
Any update on part 2?